AI-Powered Clinical Documentation for Radiation Oncology
A HIPAA-compliant tool that converts uploaded medical records into structured physician notes in minutes — replacing a workflow that costs doctors hours every day.
UI mockup with fictitious patient data. No real medical records were used.
Client
Dr. Brian Lawenda
Radiation Oncologist
Scope
AI Engineering
OCR Pipeline Architecture
HIPAA Infrastructure
Product Strategy
My Role
Led product strategy and AI architecture for a clinical documentation tool in active use on real patient records — navigating HIPAA compliance, multi-model OCR, and healthcare adoption.
Doctors are writing reports instead of seeing patients
Every consultation generates a pile of records from different providers, different systems, different formats. Imaging reports, lab results, pathology, surgical notes, referral letters. Assembling all of that into a single structured note takes hours. That's hours not spent with patients.
The workaround most doctors found is pasting records into ChatGPT. It works. It's also a HIPAA violation. Patient data going through a consumer AI tool with no BAA, no audit trail, no data retention controls. One compliance review and that workflow is over.

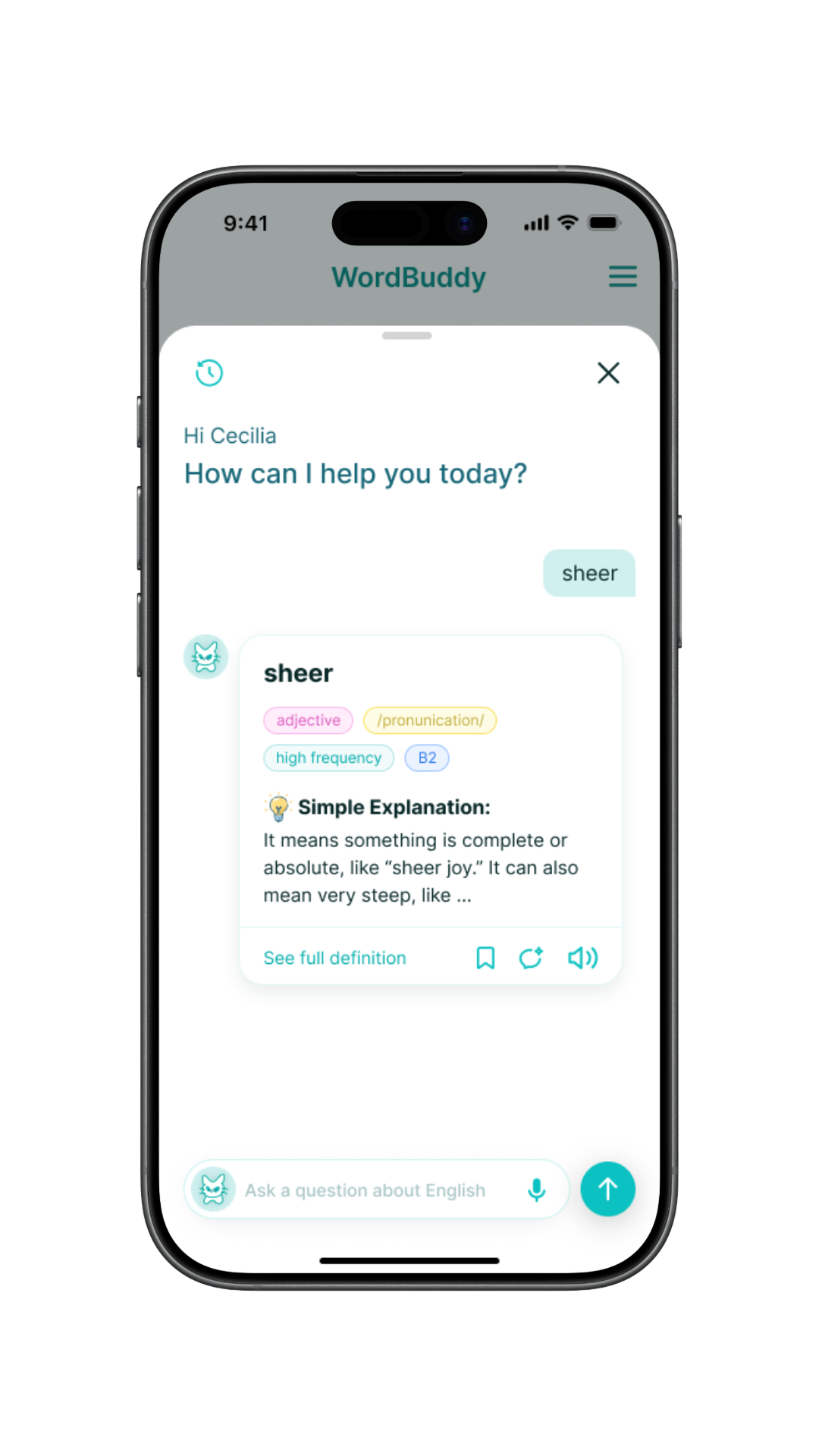
Upload records. Get a structured note. Paste into the EMR.
Doctors upload medical records (screenshots, scanned pages, PDFs) and the system extracts content using OCR, feeds it into a medical LLM, and generates a fully structured consultation note. Minutes instead of hours. HIPAA-compliant end to end.
What HIPAA compliance actually requires
HIPAA isn't a checkbox. It's an infrastructure constraint that shapes every technical decision. When your AI tool processes patient records, every layer of the stack has to account for it. Most teams underestimate what that means until they're already building.
We chose AWS as the foundation and signed a BAA (Business Associate Agreement), the legal contract that makes AWS a HIPAA-covered provider. From there, every service touching patient data had to meet the standard. That meant six things:
Encryption
All data encrypted at rest (KMS) and in transit (TLS). No exceptions.
Network Isolation
Everything runs inside a private VPC. No public-facing databases, no open ports.
Access Controls
IAM roles with least-privilege permissions. MFA enforced. No root access keys.
Logging & Audit Trails
CloudTrail for all API activity. CloudWatch for monitoring. Every action on patient data is traceable.
Data Retention
No patient records stored in databases. Everything processes in-memory and is discarded after the session.
Infrastructure Ownership
The system runs on the doctor's own AWS account. They own the infrastructure, the data, and the access controls.
From raw files to visible, verifiable output
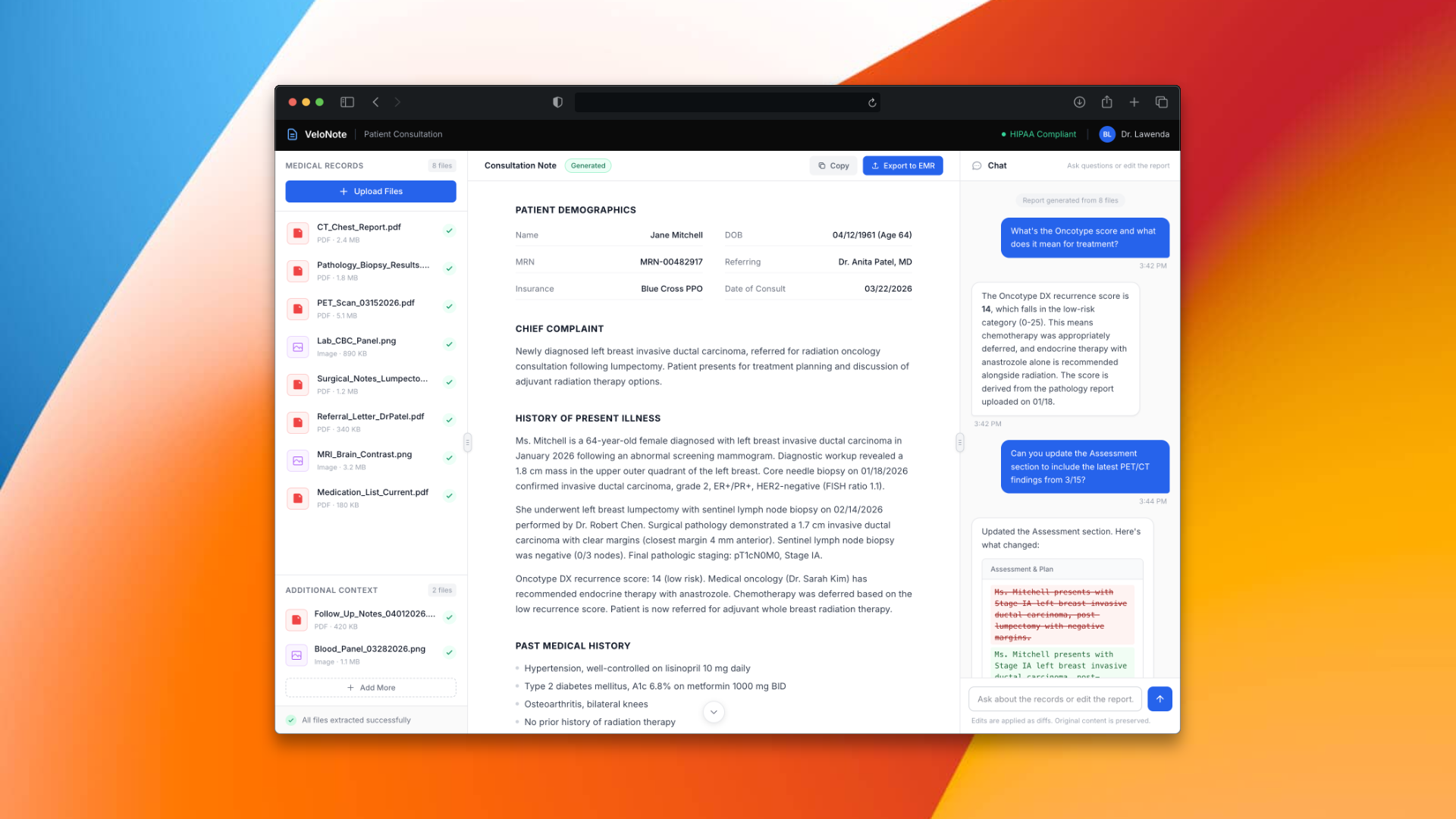
The first version fed raw PDFs and images directly into the LLM. It hit a wall fast: 7-8 file limit per call, brutal latency, and impossible unit economics. We separated extraction from generation by bringing in Mistral OCR to pull text first, then feeding clean text to the LLM. Faster, cheaper, no file limit.
But Mistral on a HIPAA-compliant provider (GCP) got rate-limited hard. New accounts processing medical documents at scale look like abuse. We batched images into single PDFs as a workaround while waiting on limit increases.
The bigger problem was accuracy. Bad extractions produced bad reports with no way to trace which file caused it. We added one UX change that solved it: show the raw OCR output for every file. Users could pinpoint the problem file instantly. For us, it turned debugging from guesswork into precision. The best validation layer turned out to be the user.
A multi-model pipeline that never silently fails
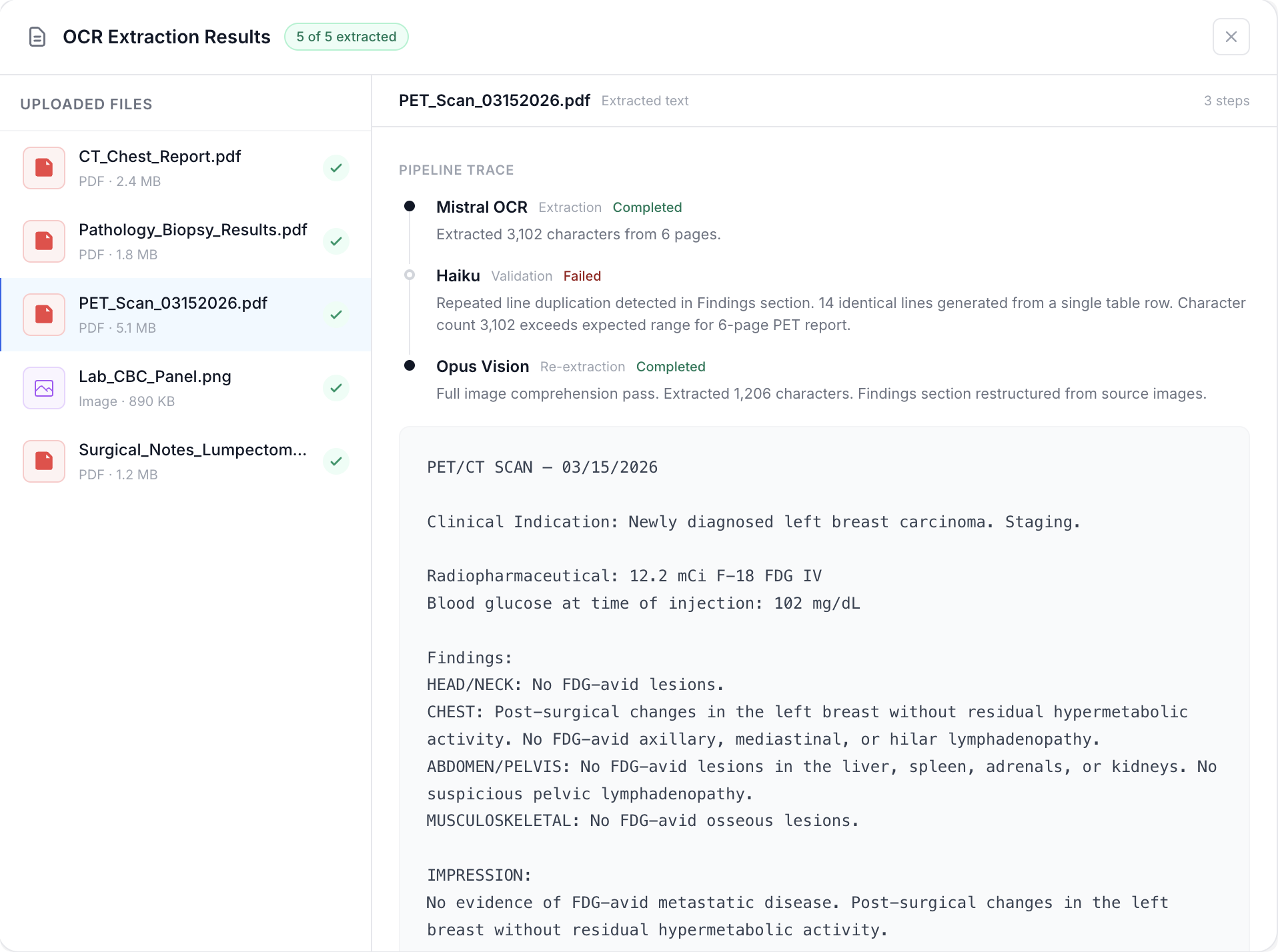
Even with visibility, edge cases kept breaking Mistral. Tables would glitch. Certain scan formats produced garbled output. We couldn't fix Mistral's model. But we could build around it.
We added a validation step: Haiku, a smaller and cheaper model, checks every OCR extraction against known glitch patterns. If it flags a file, that single file gets reprocessed through Opus, a more expensive model with full image comprehension. The rest of the batch continues untouched. If Opus also fails, the file gets excluded and flagged in the UI. Reports always generate. One bad file never tanks the batch.
The result: a pipeline that handles 30, 40, 50+ files in a single run, produces accurate extractions, and is fully HIPAA-compliant end to end. No patient data ever touches a non-compliant model.
Each iteration of this pipeline was a response to a real constraint discovered on real patient records. Not planned architecture. Earned architecture.
~15 min
Before OCR pipeline
~5 min
After full pipeline optimization
57 files
Largest batch processed
Keep the report simple. Spend the time on the pipeline.
For the MVP, the priority was report quality, not report UI. The output was a simple markdown file rendered on screen. No rich text editor, no complex formatting layer. That was deliberate. Keeping the report surface simple gave us more time to focus on the OCR pipeline, which was where the real complexity lived.
The report itself takes the OCR-extracted context from every uploaded file, synthesizes it across documents, and generates a structured consultation note. Sections that can't be populated get marked as missing rather than hallucinated. Doctors could also create and reorder their own templates, so the report generates in the structure they actually use. Same pipeline, personalized output.



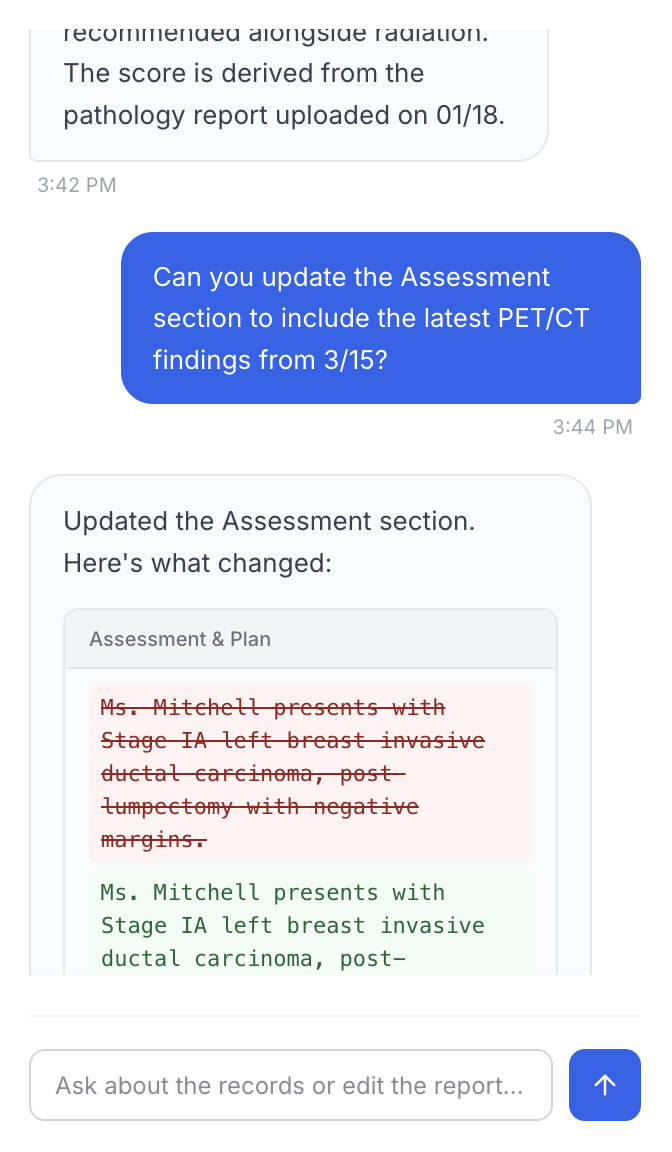
Edit the report without regenerating it
A chat panel sat alongside the report. Doctors could ask questions about anything in the generated report or the uploaded files. But the most powerful use was editing. Instead of regenerating the entire report for a small change, the doctor could just tell the chat what to fix.
Under the hood, this used diff-based editing. The same pattern that AI code editors like Claude Code use. The LLM had a tool that could search for a specific section of text in the report, find it, and replace just that part. No full regeneration, no lost context, no waiting. A targeted edit on a document that took minutes to generate in the first place.
Built for one practice. Designed to scale into many.
VeloNote was built and validated with a single radiation oncology practice. The product is live, compliance-approved, and saving doctors real time. The infrastructure was designed from the start to support multiple practices and hospital systems.
The client is now focused on bringing VeloNote into hospitals and pursuing funding to support that next phase. The foundation is there.
Multi-model OCR pipeline
Mistral, Haiku, and Opus in sequence with automated validation and graceful fallback.
Diff-based chat editing
Targeted report edits through chat without full regeneration.
97% HIPAA conformance
Compliance-approved for clinical use. Full infrastructure on the client's own AWS account.
Full ownership transfer
Infrastructure, codebase, and accounts transferred to the client's AWS, GCP, and GitHub.